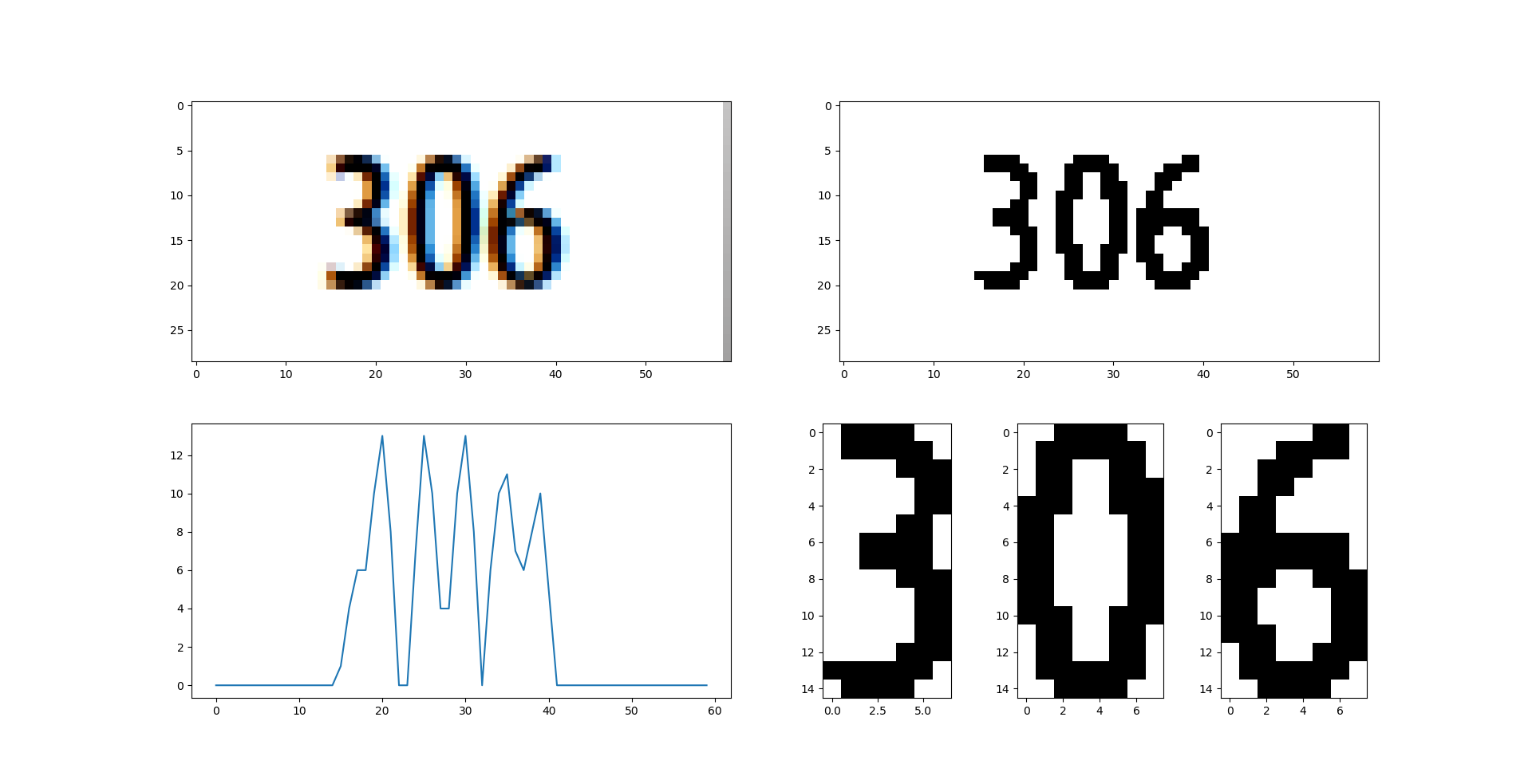
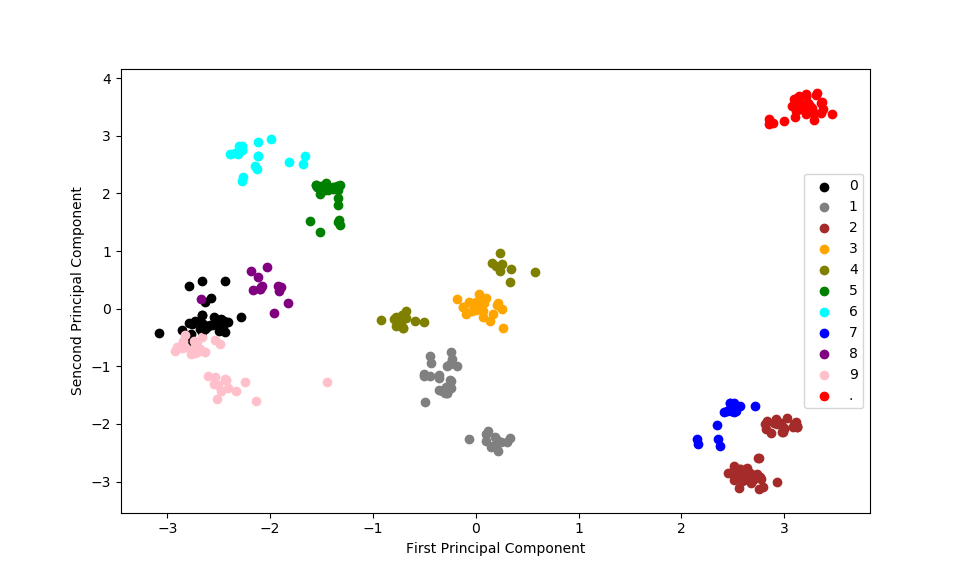
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
hash_vals = {
"0": "110000111000000110011001100110000001100000111100001111000011110000111100001111000001100010011001100110011000000111000011",
"1": "111000000000000000000000111110001111100011111000111110001111100011111000111110001111100011111000111110001111100011111000",
"2": "100000111000000111110001111110011111100111111001111110011111000111110011111000111100011111001111100111110000000000000000",
"3": "100000111000000111111000111111001111110011111001110000011100000111111000111111001111110011111100111110000000000110000011",
"4": "111100011111000111100001111000011100100111001001100110011001100100111001000000000000000011111001111110011111100111111001",
"5": "110000001100000010011111100111111001111110011111100000111000000011111000111111001111110011111100111110000000000100000011",
"6": "111110011110000111000111110011111001111110011111000000010000000100011000001111000011110000011100100110001000000111000011",
"7": "000000000000000011111001111110011111100111110011111100111111001111100111111001111100011111001111110011111000111110011111",
"8": "111000111100000110011000100111001001110010001001110000011100000110001000100111000001110000011100100111001000000011000011",
"9": "110000111000000110011001000110000011110000111100000111001001100010000000111010001111100111110001111000111000011110001111",
".": "111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111000000000000011100000"
}
def hashing(img):
"""计算哈希值"""
img = img.resize((8, 15), Image.LANCZOS)
px = np.array(img).flatten()
hash_val = (px > px.mean()).astype(int)
hash_val = ''.join(str(e) for e in hash_val)
return hash_val
def hamming(hash1, hash2):
"""计算汉明距离"""
if len(hash1) != len(hash2):
print('hash1: ', hash1)
print('hash2: ', hash2)
raise ValueError("Undefined for sequences of unequal length")
return sum(i != j for i, j in zip(hash1, hash2))
def recognize(img):
"""识别结果"""
nearness = {}
hash_val = hashing(img)
for h in hash_vals:
nearness[h] = hamming(hash_val, hash_vals[h])
expr = sorted(nearness.items(), key=lambda d: d[1])[0][0]
return expr
|